
Crie seu primeiro sistema RAG com Spring AI, Ollama e Kotlin — processe documentos, responda perguntas e mantenha seus dados privados.

O problema que começou tudo
Imagine o seguinte: você é dono de um negócio ou líder técnico que precisa processar documentos, responder perguntas de clientes e extrair insights dos seus dados. Mas toda solução de IA que você encontra:
- Custa uma fortuna em chamadas de API,
- Envia dados sensíveis para a nuvem, ou
- Parece um stack totalmente diferente da experiência do seu time.
Soa familiar?
Há três meses, enfrentei o mesmo desafio. Como engenheiro de software com mais de 10 anos de experiência no ecossistema JVM (Java, Kotlin), percebi algo: embora o Python domine as discussões sobre IA, milhões de desenvolvedores trabalham diariamente com tecnologias JVM — e eles não deveriam precisar mudar de stack para aproveitar o poder da inteligência artificial.
Foi assim que construímos um sistema RAG local (Retrieval-Augmented Generation) usando Spring AI + Kotlin + Ollama: privado, econômico e nativo para as ferramentas que os desenvolvedores JVM já dominam.
“O projeto foi criado com a crença de que a próxima onda de aplicações de IA Generativa não será apenas para desenvolvedores Python, mas será ubíqua em muitas linguagens de programação.” – Equipe de engenharia do Spring AI
O que você vai aprender
Ao final deste artigo, você entenderá:
- Por que a IA local não é apenas uma questão de privacidade — é uma verdadeira revolução.
- Como escolher o modelo de linguagem (LLM) ideal para o seu caso de uso.
- A arquitetura por trás de um sistema RAG.
- Um exemplo de código usando PDF e Markdown como fonte de conhecimento.
- Os desafios que enfrentei e como evitá-los.
Entendendo a base: Conceitos essenciais para IA local
Antes de mergulhar na implementação, vamos revisar os conceitos fundamentais que tornam esta demonstração possível.
Pense nisso como um curso rápido de vocabulário em IA: compreender esses seis elementos ajudará você a acompanhar e tomar decisões mais assertivas na sua própria implementação.
Modelos de Linguagem de Grande Escala (LLMs) são poderosas redes neurais treinadas em imensos conjuntos de texto.
Eles podem gerar, resumir, traduzir e responder perguntas usando Processamento de Linguagem Natural, atuando como reconhecedores de padrões avançados que entendem contexto e intenção.
Agentes de IA vão além.
São LLMs que raciocinam, agem e utilizam ferramentas como APIs, bancos de dados ou sistemas de arquivos. Não apenas conversam — eles executam tarefas reais.
Retrieval-Augmented Generation (RAG) conecta os LLMs aos seus próprios dados — PDFs, CSVs ou documentos internos.
Em vez de “adivinhar”, o modelo primeiro recupera trechos relevantes e depois gera respostas baseadas nesse contexto. Isso transforma um LLM genérico em um especialista no seu domínio.
Vector Stores e Embeddings tornam isso possível.
Ao converter texto em vetores semânticos, o RAG permite uma busca baseada em similaridade, compreendendo o significado, não apenas as palavras.
GGUF (GPT-Generated Unified Format) viabiliza a IA local.
Esses modelos otimizados e quantizados podem rodar de forma eficiente em notebooks ou dispositivos de borda, democratizando o acesso à IA avançada.
Por fim, Spring AI e Ollama unem tudo:
O Spring AI integra facilmente LLMs em aplicações JVM, enquanto o Ollama executa modelos quantizados localmente via CLI ou REST — dando aos desenvolvedores o poder de construir sistemas de IA privados e voltados para o local.
Por que ir para o local? (Spoiler: não é só sobre privacidade)
Executar LLMs localmente não é apenas um “truque de desenvolvedor” — é, muitas vezes, a maneira mais segura, econômica e flexível de implantar soluções de IA generativa em ambientes de produção.
O argumento a favor dos modelos de IA locais nunca foi tão forte.
Como destaca Rod Johnson (criador do Spring):
“Os modelos locais são o futuro do desenvolvimento de IA.” (Johnson, 2025)
Eles permitem integração mais profunda, comportamento transparente e personalização completa, sem dependências externas.
Na prática, os LLMs com abordagem local oferecem várias vantagens fundamentais:
- Privacidade em primeiro lugar: seus documentos sensíveis permanecem seguros no seu próprio ambiente, garantindo conformidade com o GDPR.
- Desenvolvimento econômico: modelos locais eliminam as taxas contínuas de API, permitindo iterações ilimitadas no hardware existente.
- Ecológico: ajuste o tamanho do modelo — uma IA menor significa uma pegada de carbono reduzida.
- Prototipagem mais rápida: desfrute de um desenvolvimento ágil, iterativo e sem atrasos de infraestrutura em nuvem.
- Conformidade regulatória: modelos locais proporcionam controle total de dados e atendimento a requisitos geográficos rigorosos.
Arquitetura: O que você vai construir
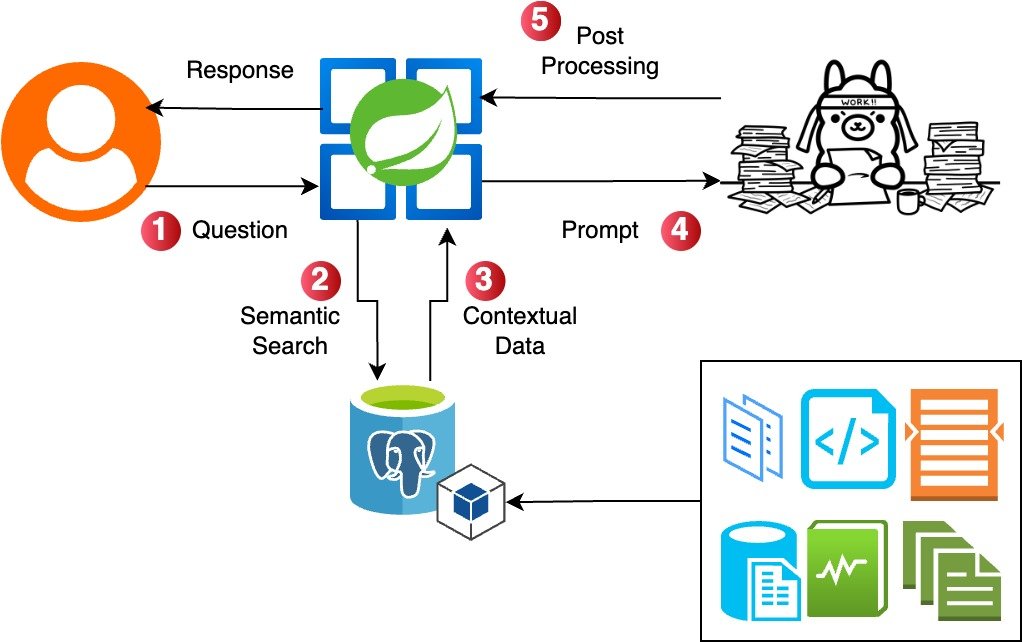
Local RAG implementation by Alejandro Mantilla inspired by Bijit Ghosh
O fluxo é direto:
- Ingestão de documentos: envie arquivos PDF ou Markdown.
- Divisão e embeddings: separe os documentos em partes e gere seus embeddings.
- Armazenamento vetorial: armazene os embeddings no PGVector.
- Processamento de consultas: o usuário faz uma pergunta.
- Recuperação: encontre os trechos relevantes por meio de similaridade vetorial.
- Geração: o LLM gera uma resposta com base no contexto recuperado.
Visão geral do stack tecnológico
Aqui está o que usei e o motivo:
- Spring AI + Kotlin: porque nem tudo precisa ser Python. O Spring AI 1.0 GA provou que é possível criar uma camada de abstração modular e poderosa sobre LLMs e bancos vetoriais.
- Ollama: o “Docker dos modelos de IA”. Torna os LLMs portáteis, acessíveis e fáceis de implantar. Roda na porta 11434 com uma API REST pronta para receber requisições.
- PGVector: PostgreSQL com extensões vetoriais. Banco de dados conhecido, agora com capacidades semânticas.
- LLMs locais: Gemma3, Mistral, Phi-2 e outros modelos otimizados para rodar eficientemente em hardware de consumo.
Codificação — Fluxo de Demonstração ao Vivo
A seguir, está a implementação principal do RAG em Kotlin:
Bloco de código 1: Configuração do banco de dados vetorial
Esta é a base para armazenar e recuperar os embeddings, parte essencial da funcionalidade RAG (Retrieval-Augmented Generation).
Toda a configuração é feita de forma programática usando o padrão Builder.
@Configuration
@EnableJpaRepositories
class VectorDatabaseConfig {
@Bean
@Primary
fun dataSource(): DataSource {
val config = HikariConfig()
config.jdbcUrl = "jdbc:postgresql://localhost:5432/ssc_agent_db"
config.username = "postgres"
config.password = "password"
config.driverClassName = "org.postgresql.Driver"
// Enable pgvector extension support
config.addDataSourceProperty("stringtype", "unspecified")
return HikariDataSource(config)
}
@Bean
fun vectorStore(
dataSource: DataSource,
embeddingModel: EmbeddingModel
): PgVectorStore {
return PgVectorStore.builder(dataSource, embeddingModel)
.withSchemaName("public")
.withTableName("document_embeddings")
// Configure vector dimensions - must match embedding model output
.withDimensions(1024)
// Set index type to HNSW for fast similarity search
.withIndexType(PgVectorStore.PgIndexType.HNSW)
// Use cosine distance for semantic similarity measurement
.withDistanceType(PgVectorStore.PgDistanceType.COSINE_DISTANCE)
// Configure batch processing for better performance
.withMaxDocumentBatchSize(10000)
// Enable automatic schema initialization
.withInitializeSchema(true)
// Enable vector table validations for data integrity
.withVectorTableValidationsEnabled(true)
// Optional: Configure HNSW-specific parameters for performance tuning
.withHnswEfConstruction(200) // Higher = better recall, slower build
.withHnswM(16) // Higher = better recall, more memory
.build()
}
}
Bloco de código 2: Processamento de documentos
Esta é a lógica central de negócios que transforma documentos empresariais brutos em conhecimento estruturado e pesquisável.
Ela lida com tarefas essenciais como ingestão de documentos, divisão inteligente de texto, geração de embeddings e armazenamento eficiente em bancos de dados vetoriais.
Esses processos formam a base da base de conhecimento que permite ao agente de IA raciocinar sobre o contexto específico da sua empresa.
Nesta configuração, modelos como mxbai-embed-large e nomic-embed-text são inicializados para gerar embeddings de alta qualidade a partir de diversos formatos, enquanto gemma3 é usado para geração de linguagem controlada e econômica, com temperatura ajustada em 0.4 (valores baixos tornam as respostas mais focadas e previsíveis, enquanto valores altos aumentam a aleatoriedade e variabilidade).
Todo o fluxo é orquestrado localmente usando o Ollama, garantindo privacidade e baixa latência.
Isso permite que o agente de IA forneça respostas inteligentes, rápidas e contextualizadas, baseadas nos dados internos do seu negócio.
spring.ai.ollama.base-url= http://localhost:11434
spring.ai.ollama.init.embedding.additional-models= mxbai-embed-large, nomic-embed-text
spring.ai.ollama.chat.options.temperature = 0.4
spring.ai.ollama.chat.options.model = gemma3
Bloco de código 3: Implementação RAG no IngestionService
Este serviço demonstra o pipeline RAG (Retrieval-Augmented Generation) em sua forma mais simples e eficaz.
O método queryRAGKnowledge executa uma busca por similaridade vetorial para encontrar os documentos mais relevantes, combina o conteúdo em uma string de contexto e cria um prompt de sistema que instrui a IA a usar apenas as informações recuperadas ou responder “IDK :(” quando não tiver certeza.
Usando o Ollama como LLM local, o sistema gera respostas fundamentadas nos próprios dados da empresa.
O serviço também gerencia a ingestão de documentos em vários formatos (PDF, Markdown, Imagens), com divisão de tokens consistente e armazenamento vetorial uniforme, tornando-se uma solução completa de gestão do conhecimento.
@Service
class IngestionService(
private val vectorStore: VectorStore,
private val pdfDocumentReader: PdfDocumentReader,
private val markdownReader: MarkdownReader,
private val imageReader: ImageReader,
private val ollamaChatModel: OllamaChatModel
) {
private val logger = LoggerFactory.getLogger(IngestionService::class.java)
fun ingest(type: IngestionType) {
when (type) {
IngestionType.PDF -> ingestPdf()
IngestionType.MARKDOWN -> ingestMarkdown()
IngestionType.IMG -> ingestImage()
}
}
private fun ingestPdf() {
logger.info("Ingesting PDF using PdfDocumentReader component")
pdfDocumentReader.getDocsFromPdfWithCatalog()
.let { TokenTextSplitter().apply(it) }
.let { vectorStore.add(it) }
logger.info("PDF loaded into vector store")
}
// ...
// ...
// ...
/**
* Main RAG query method - retrieves similar documents and generates response
* This is the core of the local AI agent's intelligence
*/
fun queryRAGKnowledge(query: String): ResponseEntity<String> {
// Step 1: Find similar documents from vector store
val information = vectorStore.similaritySearch(query)
?.joinToString(System.lineSeparator()) { it.getFormattedContent() }
.orEmpty()
// Step 2: Create system prompt with retrieved information
val systemPromptTemplate = SystemPromptTemplate(
"""
You are a helpful assistant.
Use only the following information to answer the question.
Do not use any other information. If you do not know, simply answer: IDK :(
{information}
""".trimIndent()
)
// Step 3: Build prompt with context and user query
val systemMessage = systemPromptTemplate.createMessage(mapOf("information" to information))
val userMessage = PromptTemplate("{query}").createMessage(mapOf("query" to query))
val prompt = Prompt(listOf(systemMessage, userMessage))
// Step 4: Generate response using Ollama chat model
return ollamaChatModel.call(prompt)
.result
.output
.text
.let { ResponseEntity.ok(it) }
}
}
// Supporting Data Classes and Enums
data class ChatRequest(val message: String)
data class ChatResponse(
val message: String,
val sources: List<String>,
val timestamp: LocalDateTime
)
enum class IngestionType {
PDF, MARKDOWN, IMG
}
Lições aprendidas / Dicas de desenvolvimento
💡 A IA não é mais o futuro — é o seu localhost
A diferença de desempenho entre modelos locais e em nuvem está diminuindo rapidamente.
Para muitos casos de uso, os modelos locais já são “bons o suficiente” e trazem grandes vantagens.
🔐 Privacidade + Controle = Superpoderes
Garantir a privacidade dos dados abre portas com clientes que antes nem consideravam soluções baseadas em IA.
🧩 Spring AI + Kotlin = Experiência de desenvolvimento limpa
A maturidade do ecossistema Spring, combinada com a expressividade do Kotlin, cria uma experiência de desenvolvimento que rivaliza com o Python para aplicações de IA.
🧠 Comece simples
Não tente construir um GPT-5 no primeiro dia.
Comece com um RAG básico, faça funcionar e depois adicione complexidade.
Recursos e próximos passos
Todo o código, arquivos de configuração e documentos de exemplo estão prontos para você no meu repositório do GitHub.
➡️ Repositório oficial: https://github.com/AlejoJamC/ssc-local-agent
🔧 O que você precisa para começar:
# 1. Instale o Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# 2. Baixe um modelo
ollama pull gemma3
# 3. Clone o repositório
git clone https://github.com/AlejoJamC/ssc-local-agent.git
# 4. Execute a aplicação
./gradlew bootRun
E é isso. Sem configuração em nuvem, sem chaves de API, sem cartão de crédito.
🎥 Assista à demonstração ao vivo
SSC Meetup Talk: “Your First RAG with Spring AI”
Veja a implementação completa em ação, com sessão de perguntas e respostas em tempo real.
📚 Documentação oficial e exemplos
- Spring AI 1.0 GA Release — anúncio oficial com os principais recursos.
- Awesome Spring AI Community Samples — coleção curada de implementações Spring AI.
🔍 Ferramentas para seleção de modelos
- Artificial Analysis — compare desempenho, custo e velocidade entre provedores.
- LMArena Leaderboard — ranking e comparações conduzidas pela comunidade.
- 🤗 Open LLM Leaderboard — avaliação abrangente de modelos no Hugging Face.
👉 O que vem a seguir?
Tente construir seu próprio sistema RAG.
Comece pelo repositório do GitHub, experimente diferentes modelos e descubra qual funciona melhor para o seu caso de uso.
A barreira de entrada nunca foi tão baixa.
Tem dúvidas sobre a implementação?
Quer discutir estratégias de seleção de modelos?
Deixe um comentário abaixo ou conecte-se comigo no LinkedIn.
Lembre-se: a melhor IA é aquela que você realmente usa.
E, às vezes, isso significa mantê-la local.
Referências
Liu, F., Kang, Z. and Han, X. (2024) ‘Optimizing RAG Techniques for Automotive Industry PDF Chatbots: A Case Study with Locally Deployed Ollama ModelsOptimizing RAG Techniques Based on Locally Deployed Ollama ModelsA Case Study with Locally Deployed Ollama Models’, in Proceedings of 2024 3rd International Conference on Artificial Intelligence and Intelligent Information Processing, AIIIP 2024. New York, NY, USA: ACM, pp. 152–159. Available at: https://doi.org/10.1145/3707292.3707358.
Johnson, Rod (2025) Why you should use local models. Medium. 30 May. Available at: https://medium.com/@springrod/why-you-should-use-local-models-a3fce1124c94 (Accessed: 6 July 2025).
Spring.io (2025) ‘Spring AI 1.0 GA Released’ [online image] Available at: https://spring.io/blog/2025/05/20/spring-ai-1-0-GA-released [Accessed 20 May 2025].
Mantilla Celis, J.A. (2025) ‘Build a Local AI Agent for Small Businesses [Local RAG implementation diagram], inspired by the work of Bijit, B. (2024) ‘Advanced RAG for LLMs & SLMs’, Medium, 21 April. Available at: https://medium.com/@bijit211987/advanced-rag-for-llms-slms-5bcc6fbba411 (Accessed: 18 May 2025).
#AI #RAG #SpringAI #Kotlin #LocalAI #MachineLearning #Privacy #OpenSource #Ollama #Gemma3
Comments (0)